Every token you don't send is a token you don't pay for.
Swarm-style AI development costs up to $2,500/day — not because models are expensive, but because stuck context cycles keep resending the same architecture docs, source files, and conversation history on every call. Agent Booster breaks the cycle.
pip install agent-booster[full]Python 3.10+ · MIT licensed · v0.2.19 · runs 100% locally · no code leaves your machine
Claude Code
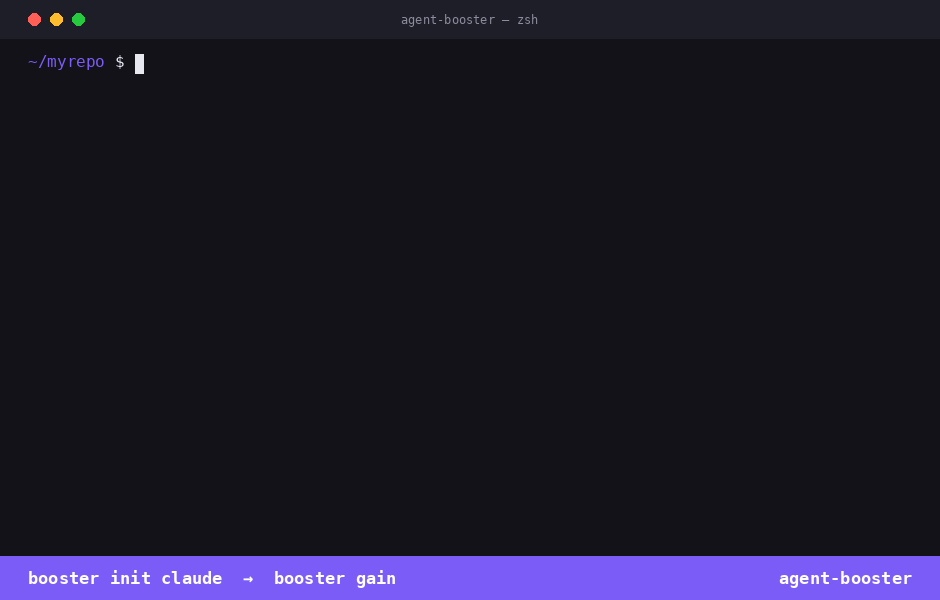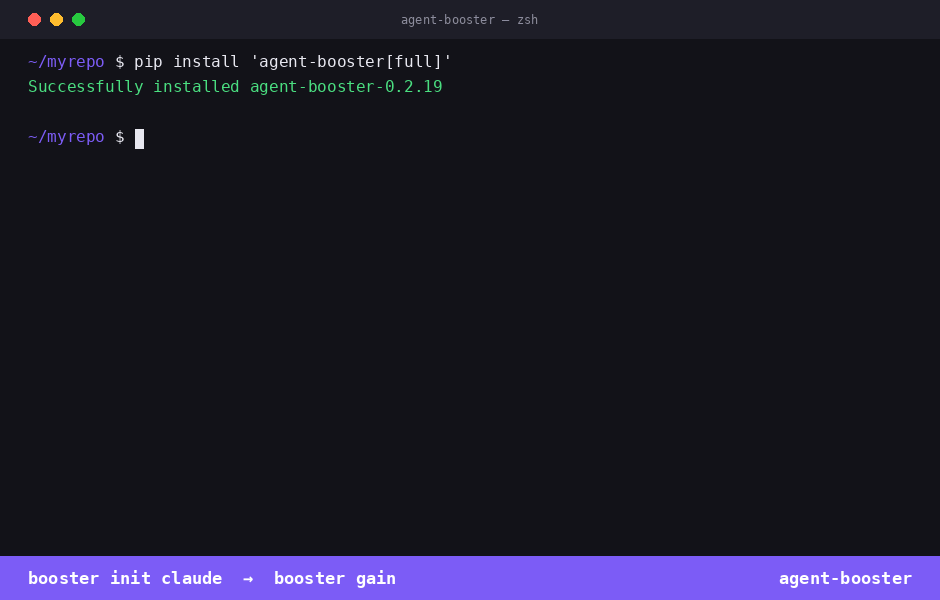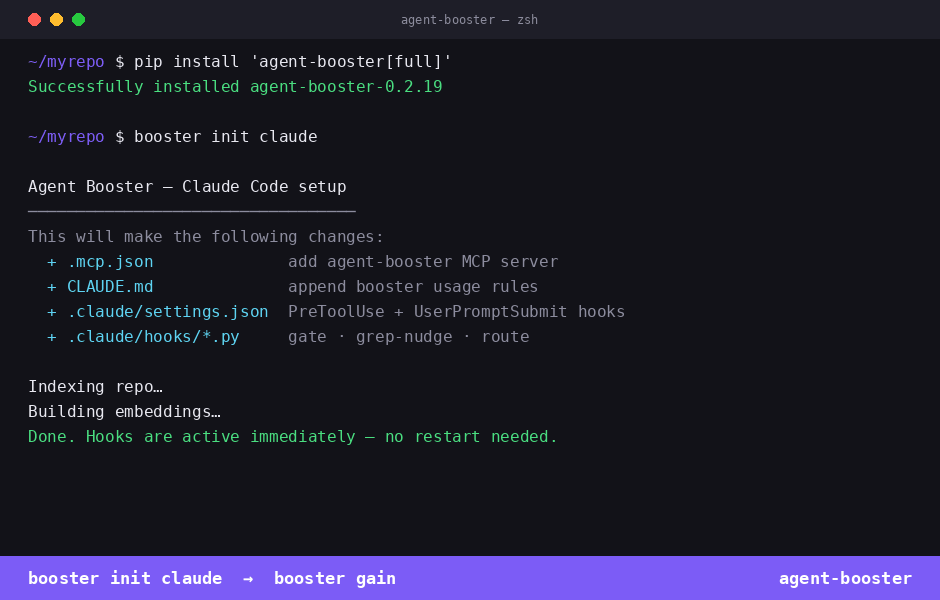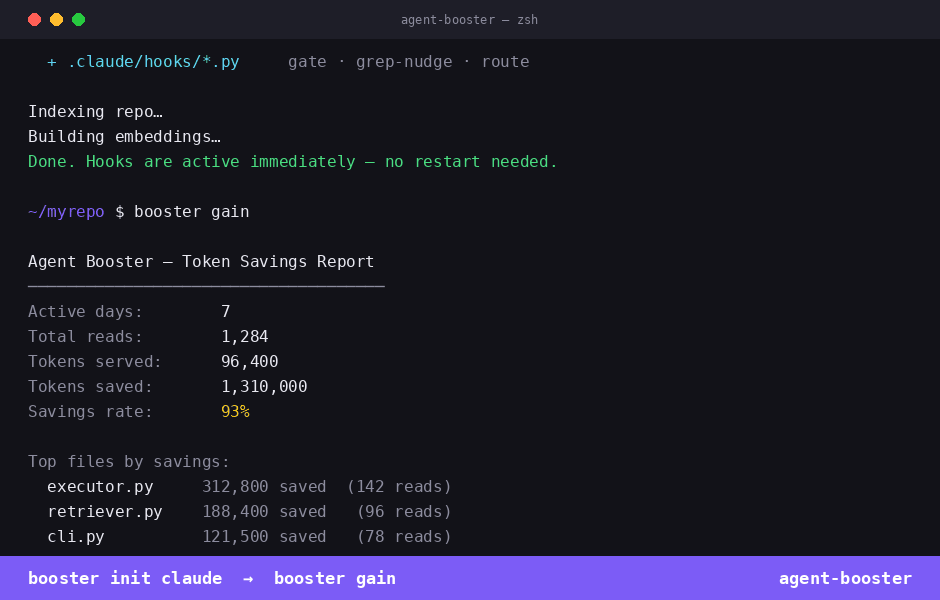
booster init claude → booster gain — less sent, less spent, same result.
OpenAI Codex
booster init codex → booster start → booster gain.
Inspiration
Standing on the shoulders of sharp thinkers.
Reuven Cohen
Agentic Engineer · Founder @ Cognitum.One
“The going rate for a single developer running Claude Code using a swarm style development is around $2.5k/day or $75k/month via Anthropic enterprise API.”
“The biggest cost in agentic development isn't the model. It's the constant replay of context. Most autonomous coding systems keep resending the same architecture documents, ADRs, source files, tool definitions, and conversation history over and over. That's where the money goes.”
“We're not optimizing models. We're optimizing information flow.”

Reuven's post articulated the problem precisely. Agent Booster is our open-source implementation of that insight — AST-level symbol routing, semantic vector search, and MCP integration built directly into your coding workflow. The concept of operating at the AST and semantic level rather than treating code as raw text comes directly from this framing.
The problem
The biggest cost isn't the model. It's context replay.
Most autonomous coding systems keep resending the same files over and over. Agent Booster operates at the AST and semantic level — routing only the pieces that actually matter to the task.
The old way
- ✕Architecture docs
- ✕ADRs
- ✕Source files
- ✕Tool definitions
- ✕Repo state
- ✕Conversation history
~$2,500/day. High token replay.
The Booster way
- ✓AST nodes
- ✓Symbols
- ✓Dependencies
- ✓Structural diffs
- ✓Semantic context
- ✓Task-specific info only
3–15x lower cost. Same output quality.
How it works
Five layers of savings, applied automatically.
Step 1
Parse & Understand
tree-sitter extracts symbols, functions, dependencies
Step 2
Semantic Diff
Detect what changed and what's relevant
Step 3
Symbol Retrieval
Pull only matching symbols from the index
Step 4
Prompt Caching
Stable context cached at 90% discount
Step 5
Smart Model Routing
route_model picks haiku, sonnet, or opus — ~4x savings on routine tasks
How we compare
Agent Booster vs CocoIndex
CocoIndex is a well-designed incremental indexing framework — great if you're building a custom pipeline. Agent Booster is the opposite: every layer ships pre-built, and you never write pipeline code.
Agent Booster
Plug-and-play · MCP-native
CocoIndex
Framework · BYO pipeline
Purpose
Plug-and-play token savings for AI coding agents
General-purpose code indexing ETL framework
MCP integration
Built-in — 4 MCP tools, works in Claude Code / Cursor / Windsurf / Codex out of the box
None — you wire your own transport layer
Setup
pip install + booster start — one command, fully bootstrapped
Write a pipeline in Python — chunking, embedding, storage are your job
Delta indexing
Built-in — SHA-256 hash + mtime, skips unchanged files automatically
Core feature — incremental pipeline execution is CocoIndex's main idea
Asymmetric embeddings
Built-in — passage: / query: E5 prefixes applied automatically
BYO — you configure the embedding function
Background daemon
Built-in — Unix socket, keeps model warm, ~50ms search vs 2–3s cold start
None — no daemon concept
File watcher
Built-in — watchdog, 2s debounce, auto re-index on every file save
Incremental pipelines (manual trigger or CI)
Model routing
Built-in — route_model picks haiku/sonnet/opus by task complexity
Not in scope
Token tracking
Built-in — booster gain reports savings per file, per session
Not in scope
Target user
Developer who wants savings now, zero custom code
Engineer building a custom indexing pipeline or RAG system
CocoIndex is OSS and worth a look if you need a custom pipeline: cocoindex-io/cocoindex-code
Architecture
Three compounding layers of token savings.
Layer 3
Agent Booster
AST + semantic routing, smart file reads — routes only the relevant symbols and functions to the model instead of full files.
Layer 2
RTK — Rust Token Killer
Token compression on tool output — strips noise from CLI, git, build, and test output before it reaches the context window.
Layer 1
Prompt caching
Stable context reuse — native to Claude Code and the Anthropic API. Repeated stable prefixes are cached at a 90% discount.
Quickstart
Up and running in two commands.
Step 1 — Install
# includes embeddings + file watcher
pip install agent-booster[full]
Step 2 — Start
# detects Claude/Cursor/Codex, wires hooks, indexes, starts daemon
booster start
Detects which AI tools are present (Claude Code, Cursor, Windsurf, Codex), wires each one automatically, indexes the project, and starts a background daemon that keeps the model warm and auto-re-indexes on every file save. Fully reversible with booster remove claude.
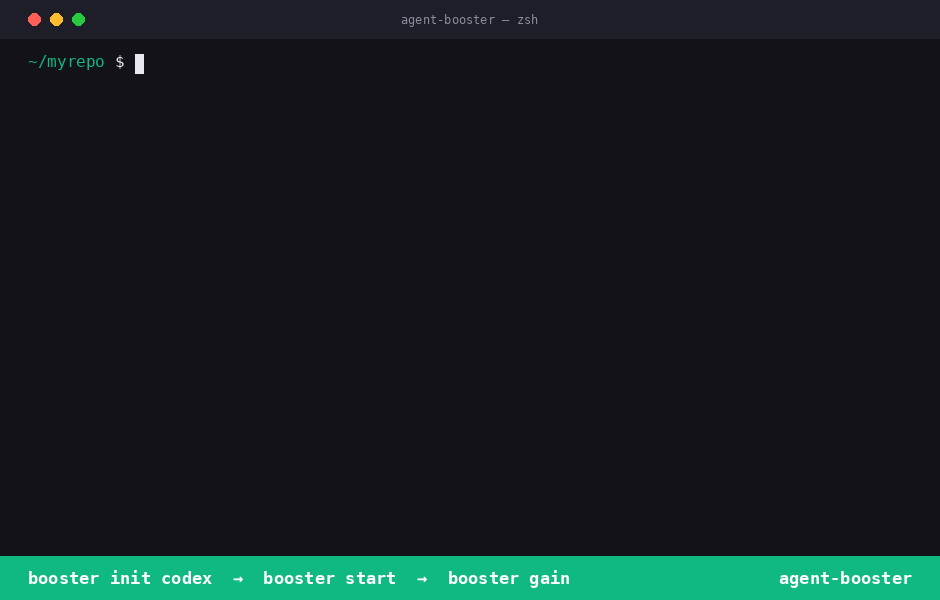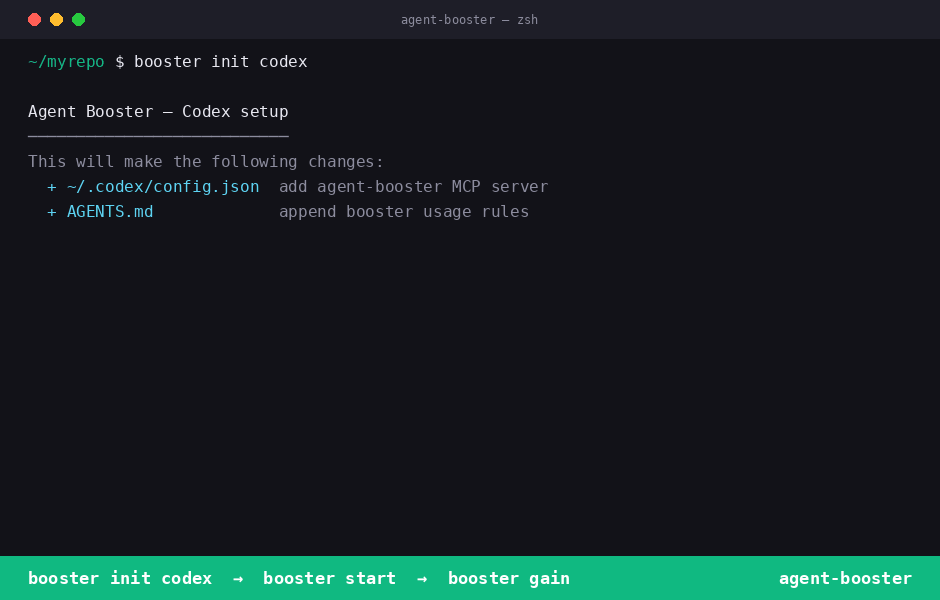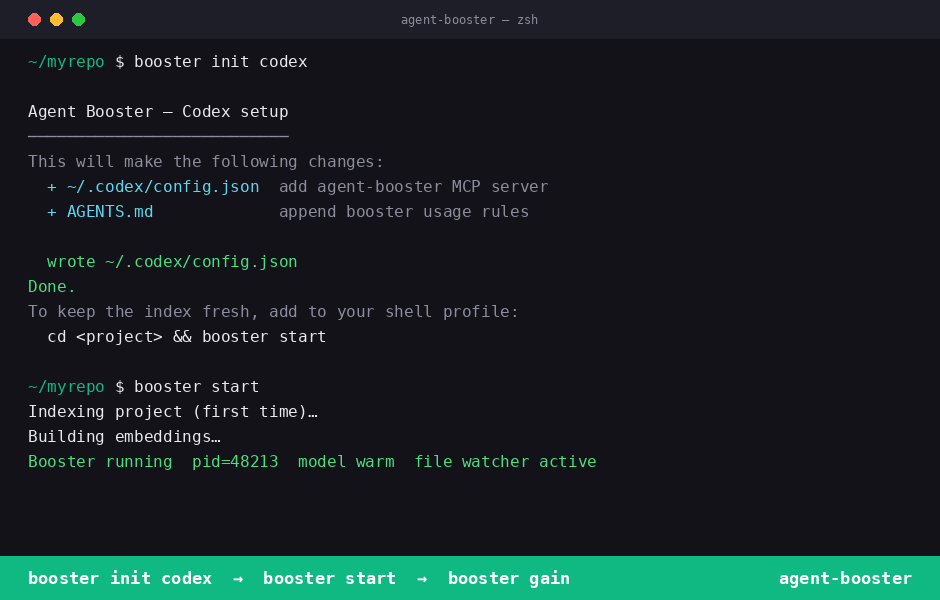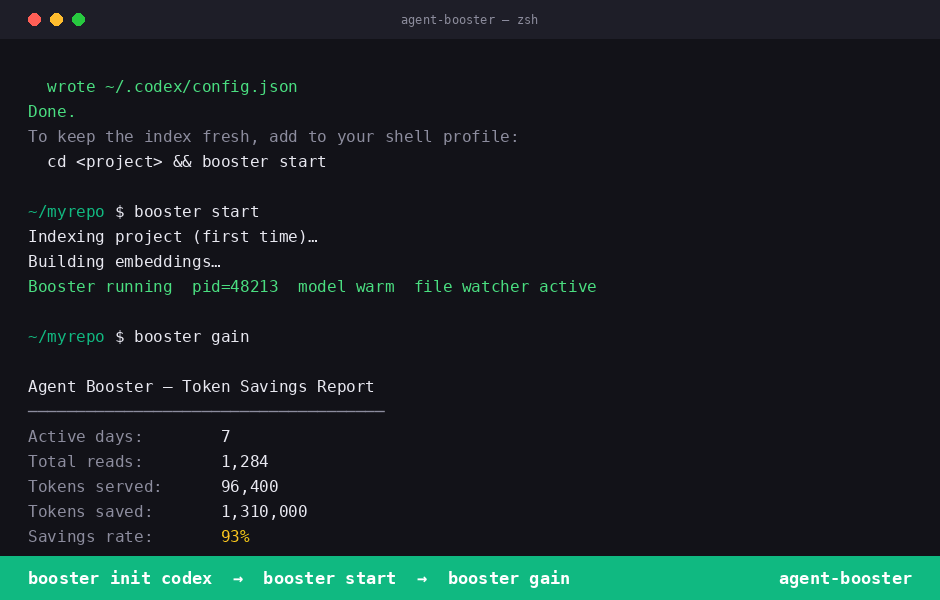
That's it — then track savings
booster gain
What's new
v0.2.16 – v0.2.18Daemon, delta indexing, and asymmetric embeddings.
Three releases shipped together. The result: booster start is the only command you need, search is instant after the first run, and re-indexing costs nothing on unchanged files.
Background daemon
booster start launches a persistent Unix socket process that keeps the embedding model loaded. search_context drops from 2–3 s cold-start to ~50 ms. Daemon survives editor restarts — it's not tied to any terminal.
File watcher
watchdog monitors the project for writes. Changed files are re-indexed within 2 seconds of a save — no manual booster index during a coding session. Daemon handles this automatically.
Delta indexing
SHA-256 hash and mtime stored per file in the SQLite index. Full re-index skips unchanged files entirely. Large repos that took seconds now finish in milliseconds. Use --force to override.
Asymmetric embeddings
Index-time vectors use a passage: prefix; query-time vectors use query:. Follows the E5 paper's asymmetric retrieval approach. Retrieval accuracy improves meaningfully over symmetric embeddings, especially for short function names.
booster start does everything
One command bootstraps the full stack: detects installed AI tools (Claude Code, Cursor, Windsurf, Codex), wires each one that isn't already wired, indexes the project, builds embeddings, and starts the daemon. On subsequent runs it just wakes the daemon.
Full changelog
Every commit, diff, and release note lives in the GitHub repo. PRs welcome.
Claude Code Plugin
One command to install everything.
Agent Booster is available as an official Claude Code plugin. One slash command installs the MCP server, wires the context skill, and you're live.
Install via Claude Code
/plugin marketplace add sseshachala/conductai
MCP server
Wires booster serve as an MCP server — smart_read, search_context, get_symbols, route_model available immediately.
Context skill
Adds the booster-context skill so Claude prefers smart_read and search_context over native Read/Grep.
Zero config
No manual .mcp.json edits. Works in every Claude Code session opened in this directory.
Then start booster in your project
# indexes, embeds, and starts the daemon automatically
booster start
Detects which AI tools are installed, wires each one, runs booster index and booster embed if the index is missing, then starts the background daemon. Nothing to run manually.
Plugin is pending review at the Anthropic plugin directory. Until then, install directly from GitHub.
Example use cases
See the difference on real tasks.
These are actual patterns from everyday coding sessions — not synthetic benchmarks.
Fixing a bug in a large service file
You need to fix a validation bug in one function inside a 1,800-line API router.
97%
token savings
Without Booster
- ✕Claude reads the full 1,800-line file
- ✕~450 tokens just to locate the function
- ✕Full file re-sent on every follow-up turn
~450 tokens per read
With Booster
- ✓smart_read(file, "fix validation in create_order") returns 42 lines
- ✓Only the matching function + its direct dependencies
- ✓Same slice reused across follow-up turns via prompt cache
~12 tokens per read
MCP Tools
Four tools. Massive context savings.
Agent Booster exposes four MCP tools — targeted symbol lookups, semantic search, smart file reads, and automatic model routing. The model sees exactly what it needs and nothing else.
get_symbols(file)Returns all functions and classes for a file from the booster index — no file read required.
search_context(task)RRF-fused search across the full codebase — merges vector similarity and keyword ranks using Reciprocal Rank Fusion so strong keyword matches surface even when embeddings are weak. Falls back to keyword-only if embeddings aren't built.
smart_read(file, task)Returns only the relevant AST symbol slices for a task using RRF-ranked selection. Applies a 5 KB gate — if matched symbols exceed 5 KB, trims to the top-3 ranked symbols with a truncation notice. Logs token savings to booster gain.
route_model(task, files?)Recommends haiku, sonnet, or opus based on task complexity — keyword signals, file count, and symbol count. Saves ~4x on routine tasks by skipping unnecessary Opus calls.
CLI Reference
Every command, and when to use it.
Most of the time you only need two: start (does everything) and gain (shows savings).
booster startOnce per project — the only command you need
Bootstraps everything: detects installed AI tools, wires each one, indexes the project, and starts the background daemon. On subsequent runs, just wakes up the daemon.
booster start --foreground to run daemon in terminal
booster stopWhen you're done or want to free memory
Sends SIGTERM to the daemon and waits for clean shutdown.
booster statusTo check what's running
Shows daemon pid, uptime, model name, and file watcher state.
booster init <platform>Manual wiring for a specific tool (optional — booster start does this automatically)
Writes MCP config, rules file, and hooks for claude, cursor, windsurf, or codex.
booster init claude --yes to skip prompt
booster remove <platform>When you want to uninstall
Cleanly removes everything init wrote — MCP entry, rules block, hook script. No residue.
booster indexManual re-index after a large refactor (daemon handles this automatically on file save)
Parses .py / .ts / .tsx / .js / .jsx files with tree-sitter. Skips unchanged files (delta indexing). Use --force to re-index everything.
booster index --force to bypass delta cache
booster embedAfter manual booster index
Rebuilds sentence-transformer vector embeddings for all symbols. The daemon handles this automatically after file-save re-indexes.
booster route "<task>"Before starting a non-trivial task
Recommends haiku, sonnet, or opus based on task complexity — keyword signals, file count, symbol count.
booster gainAny time, to see ROI
Reports total smart_read calls, tokens served vs. saved, savings rate, and top files.
booster serveAutomatic — you rarely run this directly
Starts the MCP stdio server. Called automatically by Claude Code / Cursor / Windsurf / Codex.
Compatibility
Works with every major AI coding tool.
Claude Code
booster init claudeCursor
booster init cursorWindsurf
booster init windsurfOpenAI Codex
booster init codexEach command shows exactly what files will change and asks for confirmation before writing anything. Run booster remove <platform> to cleanly undo.
Under the hood
How it's actually built.
Also by Conduct
More free tools for AI coding
Claude Code Team Kit
Claude Code scaffold for any team
Production-ready Claude Code setup across all 5 layers — CLAUDE.md, skills, hooks, subagents, and plugins — pre-configured for Enterprise, SMB, and Startup personas.
bash install.shRTK — Rust Token Killer
CLI output compression, 60–90% savings
A transparent CLI proxy that strips token noise from git, build, test, and package manager output before it reaches the model. Just prefix any command with rtk.
All tools are free, MIT licensed, and live on GitHub. See the full list at /tools.
We're not optimizing models.
We're optimizing information flow.
A workflow that costs $2,500/day with brute-force context replay can often be reduced by several multiples — while maintaining comparable output quality. Every token you don't send is a token you don't pay for.
pip install agent-booster[full]Embeddings, file watcher, and daemon all included in the [full] extra.